深度学习笔记1
线性代数
掌握好线性代数对于理解和从事机器学习算法相关工作是很有必要的,尤其对于深度学习算法而言。虽然笔者之前已经学习过线性代数这门课,并且取得了还不错的成绩,但是笔者还是决定将深度学习涉及的线代知识在进行一遍巩固。
基础知识
张量:在有些情况下,我们会讨论坐标超过两维的数组。一般的,一个数组中的元素分布在若干维坐标的规则网络中,我们称之为张量。我们使用字体A来表示张量”A”。张量A中坐标为(i, j, k)的元素记为Ai, j, k
分析: Ax = b 的方程有多少解,我们可以将A的列向量看作从原点出发的不同方向,确定有多少种方法可以到达向量b。在这种观点下,向量x中的每个元素表示我们应该沿着这些方向走多远,即xi表示我们需要沿着第i个向量的方向走多远: Ax = ∑ixiA:,i 一般而言,这种操作称为线性组合。形式上,一组向量的线性组合 ,是指每个向量乘以对应标量系数之后的和,即 ∑iciv(i) 一组向量的生成子空间是原始向量线性组合后所能抵达的点的集合
确定Ax = b是否有解,相当于确定向量b是否在A列向量的生成子空间中。这个特殊的生成子空间被称为A的列空间,或者A的值域。
其实上面就是线代的本质,很多公式定理从上面的角度来考虑就很容易了。
范数
有时,我们需要衡量一个向量的大小。在机器学习中,我们经常使用称为范数的函数来衡量向量大小。形式上,Lp范数定义如下 $$ ||x||_p=(\sum_i|x_i|^p)^{\frac{1}{p}} $$ 其中p ∈ ℝ, p ≥ 1
范数(包括Lp范数)是将向量映射到非负值的函数。直观上来说,向量x的范数衡量从原点到点x的距离。更严格地说,范数是满足下列性质地任意函数:
- f(x) = 0 ⇒ x = 0
- f(x + y) ≤ f(x) + f(y)
- ∀α ∈ ℝ, f(ax) = |a|f(x)
这里范数定义其实很有意思,我反正看完这个定义了之后就有一种感觉,很奇妙地感觉,但是我真地没法表述出来,请读者见谅
当p = 2时,L2范数称为欧几里得范数。它表示从原点出发到向量x确定的点的欧几里得距离。L2范数在机器学习里面出现得十分频繁,经常简化为||x||,略去了下标2。平方L2也经常用来衡量向量得大小,可以简单的通过点积xTx计算
平方L2范数在数学和计算上都比L2范数本身更方便。例如,平方L2对于x中每个元素的导数只取决于对应的元素,而L2范数对每个元素的导数和整个向量相关。但是在很多的情况下,平方L2范数也有可能不受欢迎,因为它在原点附近增长得十分缓慢。在某些机器学习应用中,区分恰好是零得元素和非零但值很小得元素是很重要得。在这些情况下,我们转而在各个位置斜率相同,同时保持简单得数学形式:L1范数。L1范数可以简化如下: ||x||1 = ∑i|xi| 当机器学习问题中零和非零元素之间得差异非常重要时,通常会使用L1范数。每当x中某个元素从0增加到ϵ,对应得L1范数也会增加ϵ
有时候我们会统计向量中非零元素得个数来衡量向量得大小。有些作者将这些函数称为“L0范数”,但是这个术语在数学意义上是不对的。向量的非零元素的数目不是范数,因为对向量缩放α倍不会改变该向量非零元素的数目。因此,L1范数经常作为表示非零元素数目的替代函数。
另外一个经常在机器学习中出现的范数是L∞,也被称为最大范数。这个范数表示向量中具有最大篇幅的元素的绝对值: ||x||∞ = maxi|xi| 有时候我们可能希望衡量矩阵的大小。在深度学习中,最常见的做法是使用Frobenius范数,即 $$ ||A||_F=\sqrt{\sum_{i,j}A_{i,j}^2} $$ 其类似于向量的L2范数
两个向量的点积可以用范数来表示,具体如下: xTy = ||x||2||y||2cos θ 其中θ表示x和y之间的夹角。
对角矩阵
只在主对角线上含有非零元素,其他位置都是零。形式上,矩阵D是对角矩阵,当且仅当对于所有的i ≠ j, Di, j = 0。我们已经看到过一个对角矩阵,其对角元素全是1。我们用diag(v)表示对角元素由向量v中元素给定的一个对角方阵:单位矩阵,其对角元素全部是1。我们用diag(v)表示对角元素由向量v中元素给定的一个对角方阵。对角矩阵受到关注的部分原因是对角矩阵的乘法计算很高效。计算乘法diag(v)x,我们只需要将x中每个元素xi放大vi倍,换言之,diag(v)x = v⨀x计算。计算对角方阵的逆矩阵也很高效。对角方阵的逆矩阵存在,当且仅当对角元素都是非零值,在这种情况下,diag(v)−1 = diag([1/v1, ⋯, 1/vn]T)。在很多情况下,我们可以根据任意矩阵导出一些通用的机器学习方法,但是通过将一些矩阵限制为对角矩阵,我们可以得到计算代价较低的(并且简明扼要的)算法。
并非所有的对角矩阵都是方阵。长方形的矩阵也有可能是对角矩阵。非方阵的对角矩阵没有逆矩阵,但是我们仍然可以高效地计算它们地乘法。(虽然一时半会不会知道有什么用,不过先记着吧,说不定就有用呢?)
特征分解
这里的知识虽然在任意一本线性代数的教材里面都会仔细介绍,但是由于笔者在大一的线性代数学习不够扎实,还是决定再整理一遍。
特征分解是使用最广的矩阵分解之一,即我们将矩阵分解成一组特征向量和特征值。
方阵A的特征向量是指与A相乘之后相当于对该向量进行缩放的非零向量v Av = λv 其中标量λ称为这个特征向量对应的特征值。(类似地,我们也可以定义左倾特征向量vTA = λvT),但是我们通常更关注右特征向量。
如果v是A的特征向量,那么任何缩放之后的向量sv(s ∈ ℝ, s ≠ 0)也是A的特征向量。此外,sv和v有相同的特征值。基于这个原因,通常我们只考虑单位特征向量。
假设矩阵A有n个线性无关的特征向量v(1), ⋯, v(n),对应着特征值{λ1, ⋯, λn}。我们将特征向量连接成一个矩阵,使得每一列都是一个特征向量:V = [v(1), ⋯, v(n)]。类似地,我们也可以将特征值连接成一个向量λ = [λ1, ⋯, λn]T。因此,A的特征向量分解可以记作 A = Vdiag(λ)V−1 我们已经看到了构建具有特定特征值和特征向量的矩阵,能够使我们在目标方向上延生空间。然而,我们也常常希望将矩阵分解成特征值和特征向量,这样可以帮助我们分析矩阵的特定性质,就像质因数分解有利于我们理解整数。
不是每一个矩阵都可以分解成特征值和特征向量。在某些情况下,特征分解存在,但是会涉及到复数而非实数。幸运的是,在本书中,我们通常只需要分解一类简单分解的矩阵。具体来说,每个实对称矩阵都可以分解成实特征向量和实特征值: A = QBQ−1 其中Q是A的特征向量组成的正交矩阵,B是对角矩阵。特征值Bi, i对应的特征向量是矩阵Q的第i列,记作Q:,i。因为Q是正交矩阵,我们可以将A看作沿v(i)延展λi倍的空间,如下图所示。
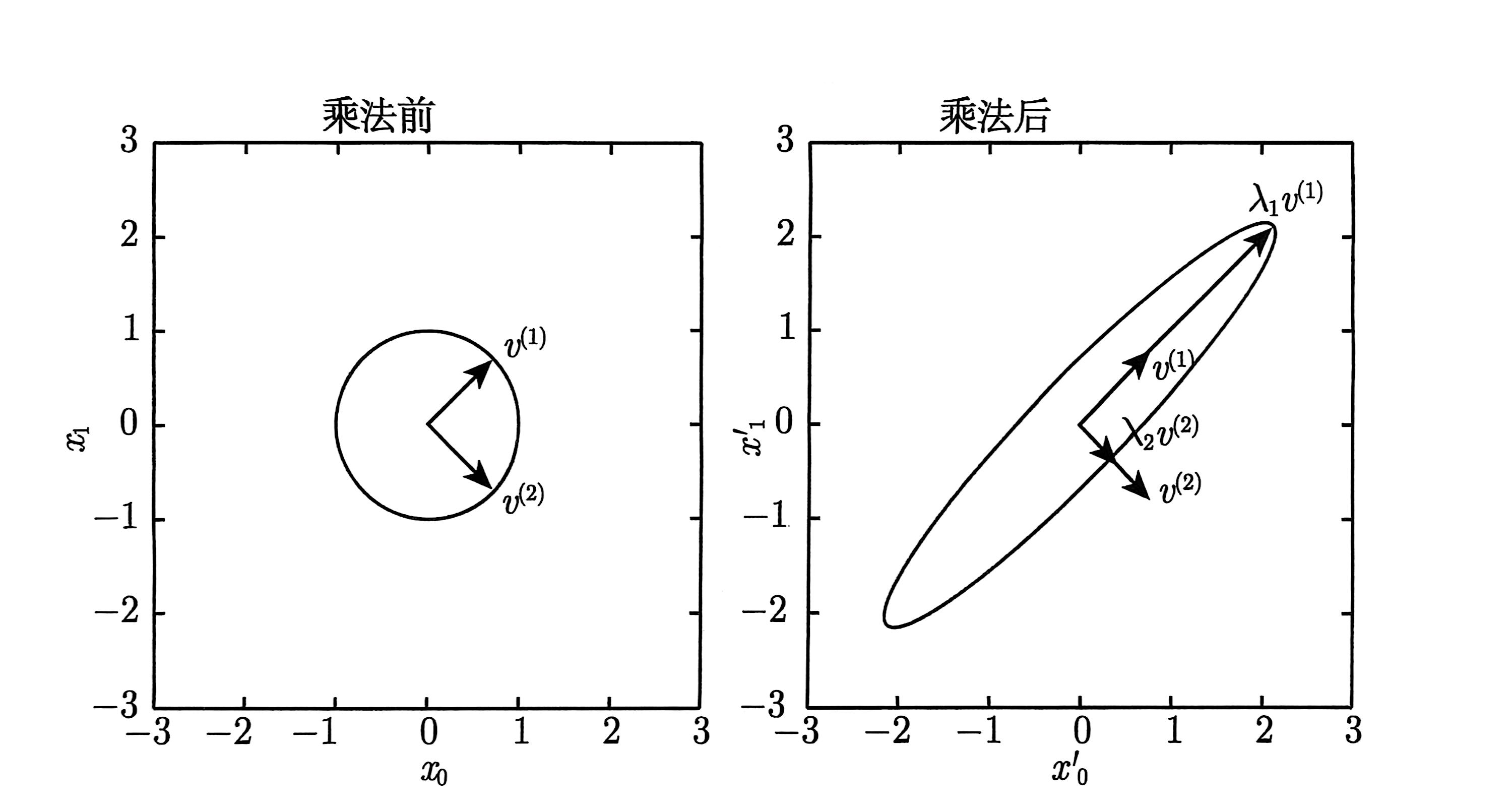
这张图实在是太美妙了,很多我没有办法理解的数学含义,这里看一下就懂了
虽然任意一个是对称矩阵A都有特征分解,但是特征分解可能并不唯一。如果两个或多个特征向量拥有相同的特征值,那么在由这些特征向量拥有相同的特征值,那么在由这些特征向量产生的生成子空间中,任意一组正交向量都是该特征值对应的特征向量。因此,我们可以等价地从这些特征向量中构成Q作为替代。按照惯例,我们通常按降序排列B中地元素。在该约定下,特征分解唯一,当且仅当所有地特征值都是唯一的。
矩阵的特征分解给了我们很多关于矩阵的有用信息。矩阵是奇异的,当且仅当含有零特征值。实对称矩阵的特征分解也可以用于优化二次方程f(x) = xTAx,其中限制||x||2 = 1。当x等于A的某个特征向量时,f将返回相应的特征值。在限制条件下,函数f的最大值是最大特征值,最小值也是最小特征值。
参考资料:《深度学习》lan Goodfellow Yoshua Bengio Aaron Courvile 著